@Hoants:
Notevibes (in its free version) is restricted to 200 characters per query. For longer texts, you need to split the text into several parts and then combine the mp3 files afterwards.
In case of the TonUINO project this is no restriction since it is using very short text fragments, but your text is longer than 200 characters.
Hi @Peer
In Notevibes free version you can convert text to speech under 3000 or 4000 characters.
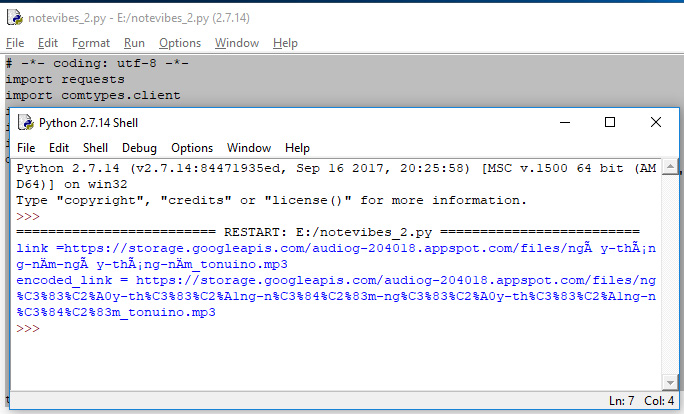
You code get error when convert unicode text like that: " Ngày tháng năm ngày tháng năm" print(link) https://storage.googleapis.com/audiog-204018.appspot.com/files/ngà y-tháng-nÄm-ngà y-tháng-nÄm_tonuino.mp3
But the correct link is: https://storage.googleapis.com/audiog-204018.appspot.com/files/ngày-tháng-năm-ngày-tháng-năm_tonuino.mp3
The German version notevibes.com/de/ notes says that there is a restriction to 200 characters, which I cited:
Erstellen Sie ein Konto, um eine unbegrenzte Nutzung zu erhalten. Kostenlose Version auf 200 Zeichen begrenzt. Nur für den persönlichen Gebrauch.
However, at the bottom of the same website the restriction is said to be 5000 characters…
The problem with the Unicode characters is, that the python function urllib.urlretrieve is not able to parse unicode urls. You need to convert the link before calling urlretrieve. This can be done in the following way:
I think, I found the problem: The link which needs to be extracted from the website is not unicode-encoded, but treated as if it were. When I replace req.text by req.content, it is interpreted as simple 8 bit text and everything works fine:
Hi, könntest du eine Schritt für Schritt Anleitung schreiben?
Ich kenn mit mit python leider null aus. Ich habe es mit der google cloud platform Variante Probiert, hab aber keine Kreditkarte und das mit dem Bankkonto bekomm ich iwie nicht ausgewählt.
Ok schade Trotzdem danke. Weißt du ob es ein Programm gibt, mit dem ich gut und einfach vorhandene mp3´s mit einer erstellten Sprachdatei verbinden kann? Am liebsten wäre mir eine batch oder ähnliches. Ich habe mp3directCut aber da muss ich jede Datei einzeln zusammenfügen.